
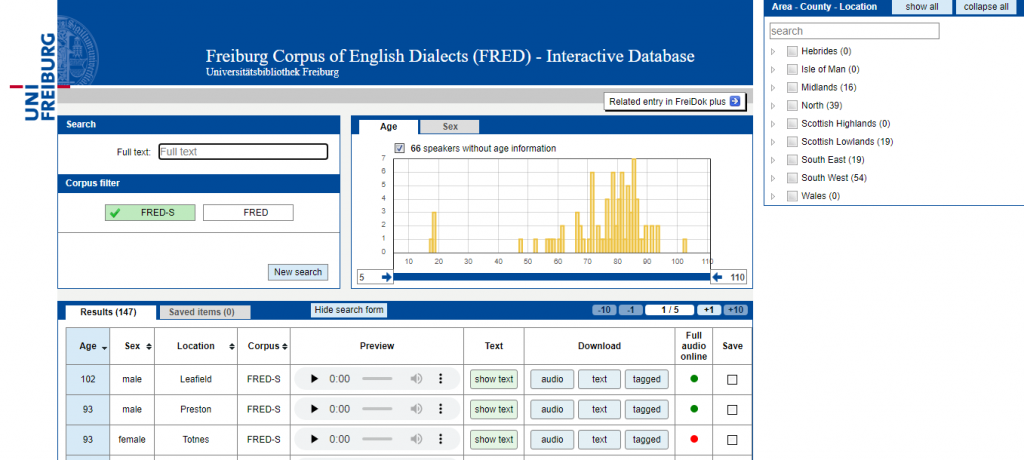
The Freiburg Corpus of English Dialects (FRED) is a monolingual spoken-language database of traditional English dialects. It samples approximately 2.5 million words and is estimated to be based on about 300 hours of recorded speech. The corpus contains full-length transcripts of 372 oral history interviews (partly available as digitised audio files) with male and female speakers from 163 different locations in 43 different counties. FRED covers 9 major dialect areas in the British Isles and is thus an extensive database for both research on single dialects and cross-dialectal studies.
FRED was compiled by the project group ‘English Dialect Syntax from a Typological Perspective’ at the English Department of Freiburg University under the supervision of Professor Bernd Kortmann. It was funded by the Deutsche Forschungsgemeinschaft under grant No. Ko-1181/1,2 from 2000 to 2005. The primary aim of compiling FRED was to provide a sound database that helps strengthen research on morphosyntactic variation in the British Isles.
A subset of FRED is openly available through the FRED Interactive Database and from The Freiburg Corpus of English Dialects Sampler (FRED‑S).
FRED ist jetzt auch in DBIS verzeichnet.